Diffusion Model¶
约 929 个字 预计阅读时间 4 分钟
总览 ¶
DDPM(Denoising Diffusion Probabilistic Models)的核心是两件事:
- 前向扩散:把真实数据逐步加噪,最后变成高斯噪声。
- 反向扩散:训练模型逐步去噪,从噪声还原出数据。
主线可以概括为:forward -> reverse -> optimization(ELBO) -> training -> sampling。
前向扩散是为了反向扩散训练 Noise Predictor 作为训练数据
前向扩散(Forward Process)¶
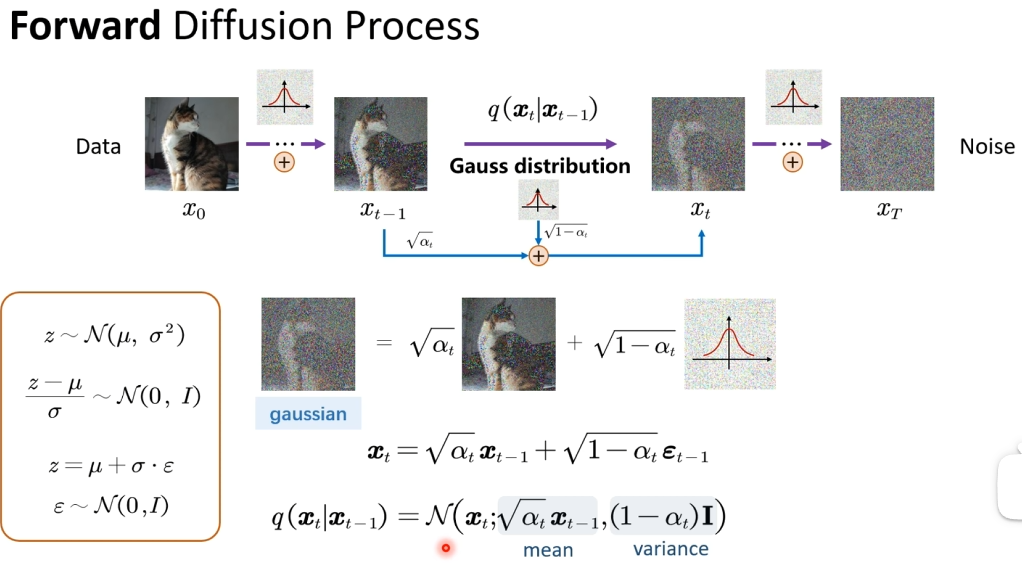
设数据为 \(x_0\),时间步 \(t=1,\dots,T\),噪声调度为 \(\beta_t \in (0,1)\),并定义: $$ alpha_t = 1-beta_t,quad bar{alpha}t = prodalpha_s $$}^{t
前向一步马尔可夫过程:
前向闭式:
等价重参数化:

直观理解
当 \(t\) 增大时,\(\bar{\alpha}_t\) 变小,图像信号衰减、噪声占比上升,最终接近纯高斯噪声。
反向扩散(Reverse Process)¶
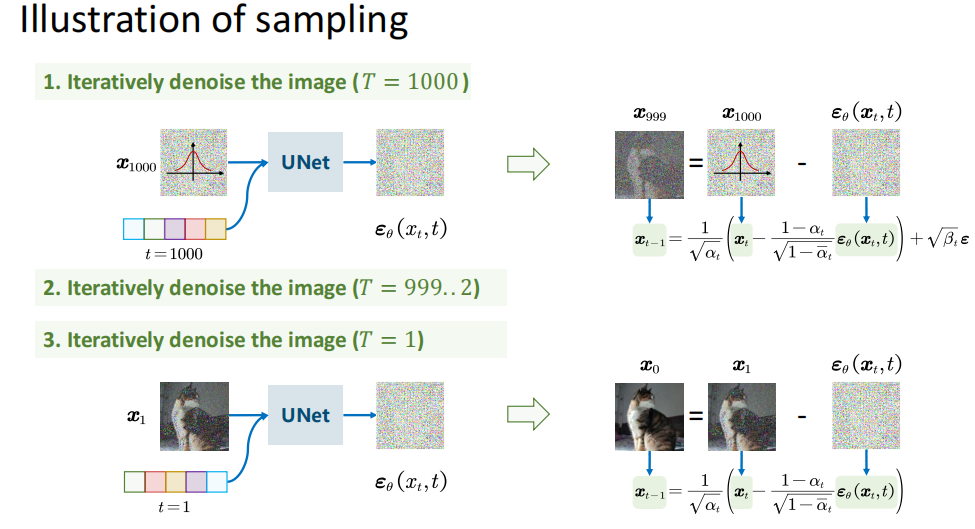
这里面 Denoise 的模块和参数是完全一样的,但是噪声的模糊程度是不一样的,因此引入了一个新的参数 step(Time Embedding)。
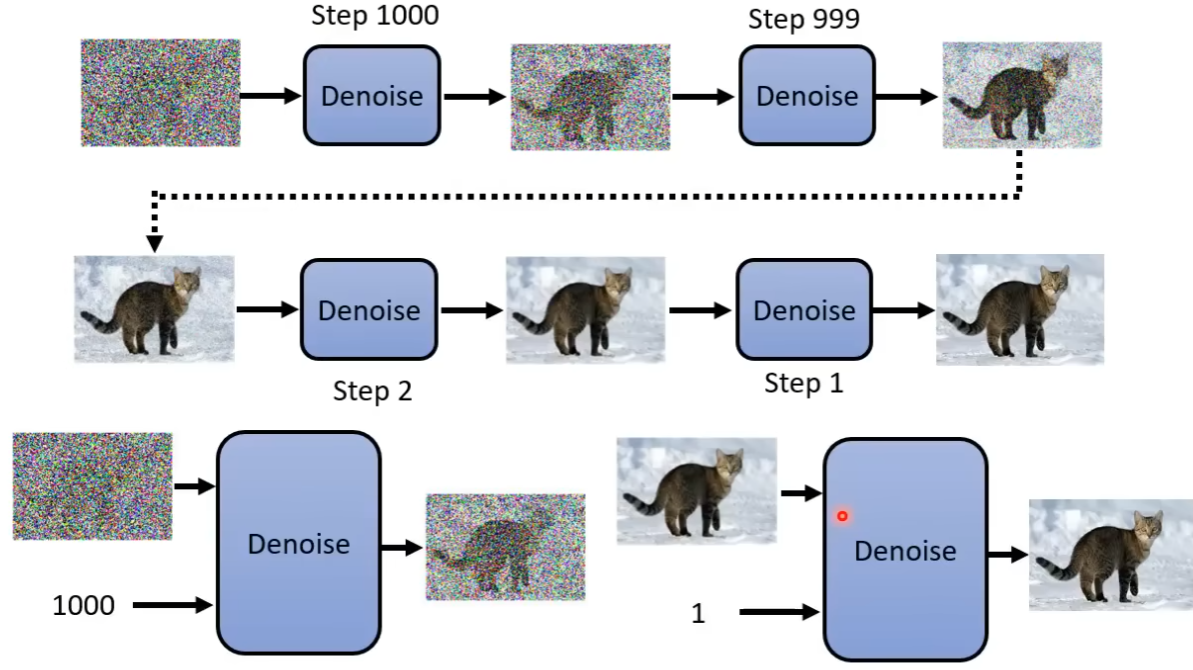
上面是一个图简介,但实际上并不是简单的加噪声,详细的数学推导如下
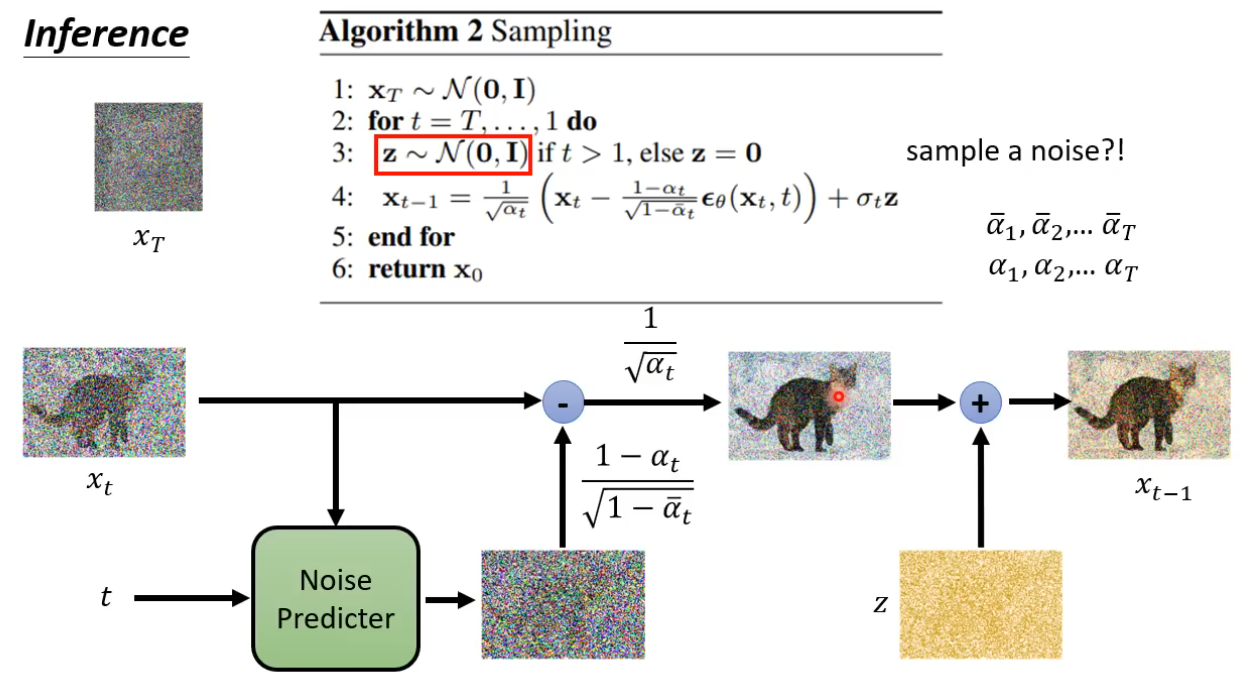
真实后验 \(q(x_{t-1}|x_t)\) 直接求很难,因此用神经网络近似: $$ p_theta(x_{t-1}|x_t)=mathcal{N}left(x_{t-1};mu_theta(x_t,t), {textstyle sum_{theta }} (x_t,t)right) $$
同时,由于 \(x_{t-1}\) 只与 \(x_t\) 有关,加入 \(x_0\) 不会影响结果,因此这里引入了 \(q(x_{t-1}|x_t,x_0)\)
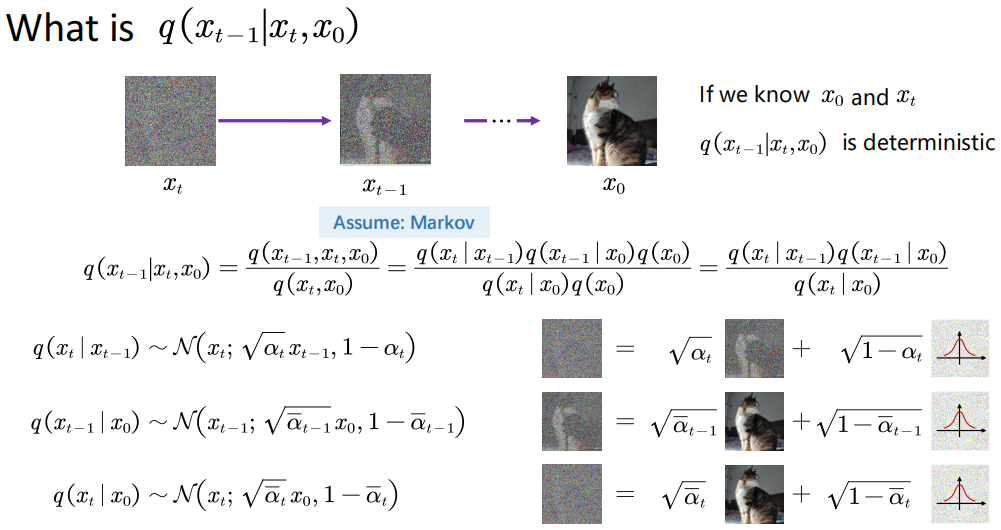
从上图中可以看到,其实 \(q(x_{t-1}|x_t,x_0)\) 是一个确定的高斯分布,也就是说 可以仅通过最后的 \(x_T\) 以及最初的 \(x_0\) 可以得到中间任意一个过程
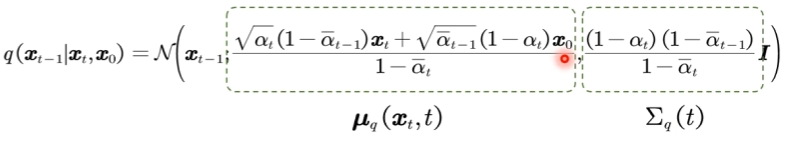
上图可以看出,方差是一个定值,因此,唯一的未知量是 \(x_0\), 因此下面要消掉 \(x_0\)

现在只有 \(\epsilon_t\) 是未知的,因此 Deffusion 做的就是去用神经网络模拟这个噪声。
DDPM 常用“预测噪声”参数化:网络输出 \(\epsilon_\theta(x_t,t)\),再由它构造均值:
采样时(从 \(x_T\sim\mathcal{N}(0,I)\) 开始
当 \(t=1\) 时通常不再加随机噪声(令 \(z=0\)
损失函数 ¶
最大似然目标:
通过变分推导可得到 ELBO:
上述 KL 散度中,对损失函数影响最大的是中间一项,因此可以化简如下
为什么通常预测噪声而不是直接预测 \(x_0\)?
噪声在不同时间步的统计形式更一致,目标尺度更稳定,训练通常更容易收敛。
训练与采样流程 ¶
训练
- 采样真实样本 \(x_0\)、时间步 \(t\)、高斯噪声 \(\epsilon\)
- 用闭式公式构造 \(x_t\)
- 输入 \((x_t,t)\) 到 UNet,输出 \(\epsilon_\theta\)
- 用 \(\mathcal{L}_{\text{simple}}\) 回传更新参数训练 UNet
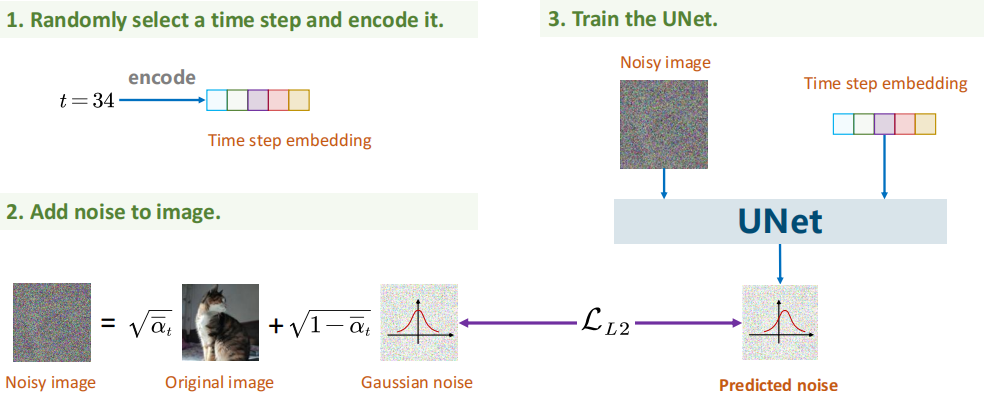
采样
- 从 \(x_T\sim\mathcal{N}(0,I)\) 开始
- 对 \(t=T,T-1,\dots,1\) 迭代去噪得到 \(x_{t-1}\)
- 最终得到生成样本 \(x_0\)