Stable Diffusion¶
约 161 个字 预计阅读时间 1 分钟
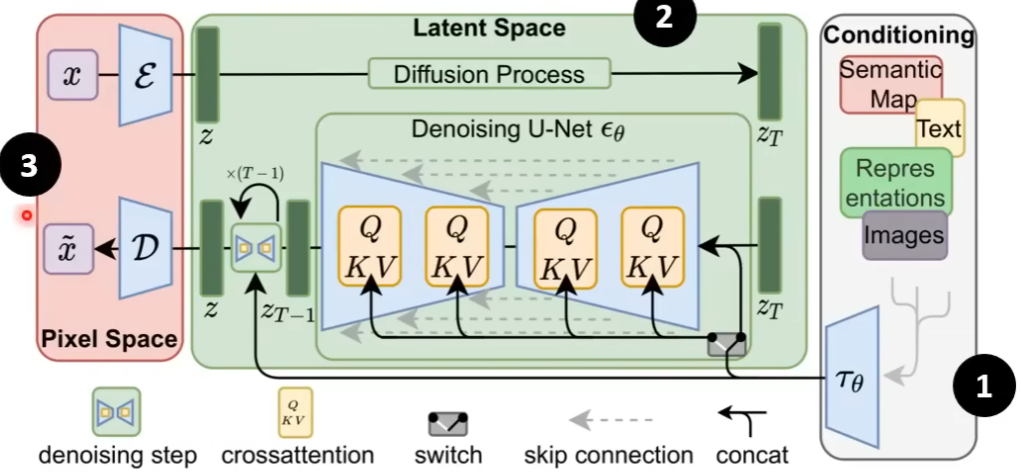
框架 ¶
Text Encoder¶
文字的 Encoder 对后面的结果影响很大
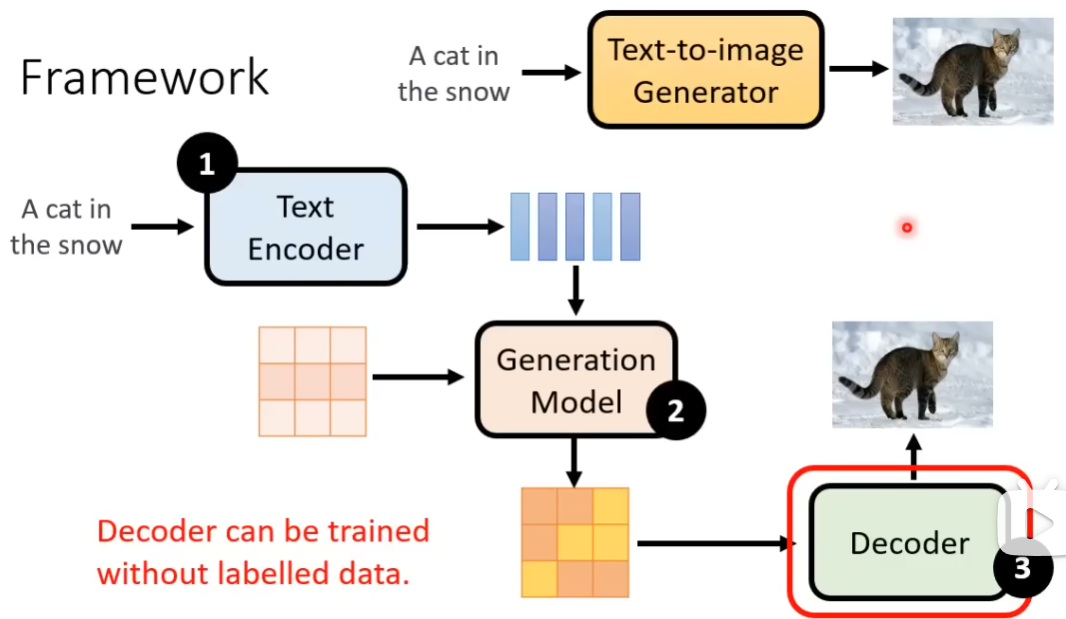
Generation Model¶
这里的方法也是一样,首先拿出在训练 Decoder 中的 Encoder,通过照片输出一个中间产物,然后加入噪声得到一个新的中间产物,不断如此。
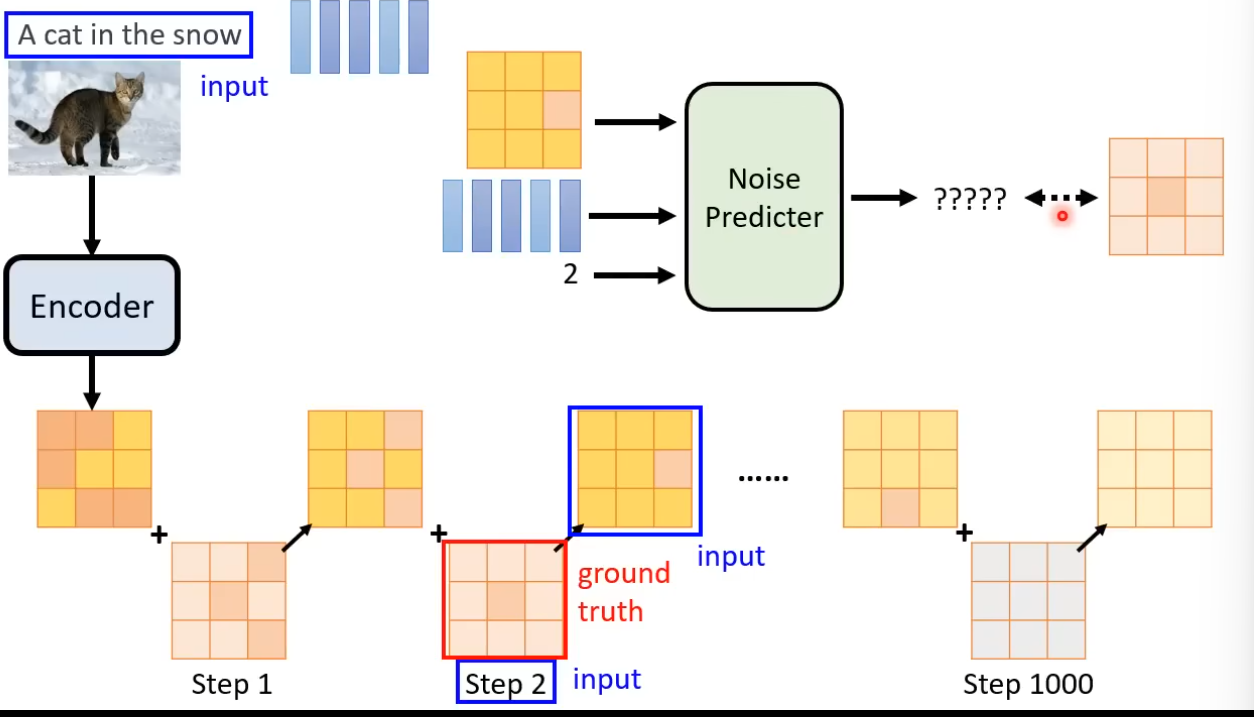
然后设计一个 Noise Predicter 通过文字 Embedding 和中间产物得到噪声,从而实现 Generation Model 的设计
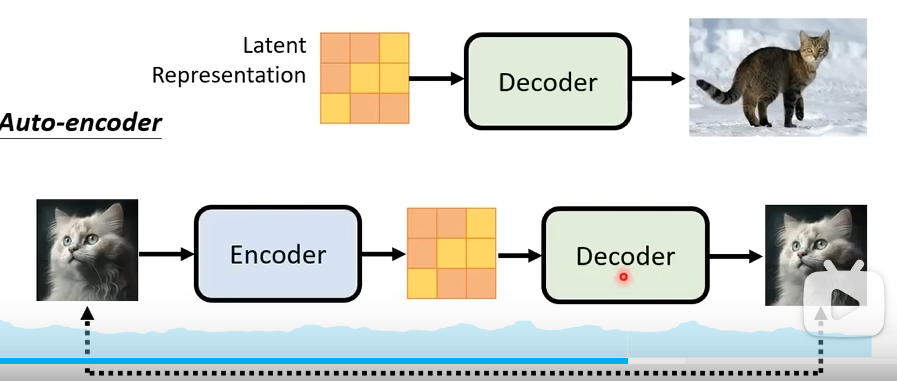
Decoder¶
Decoder 的训练不需要文字数据
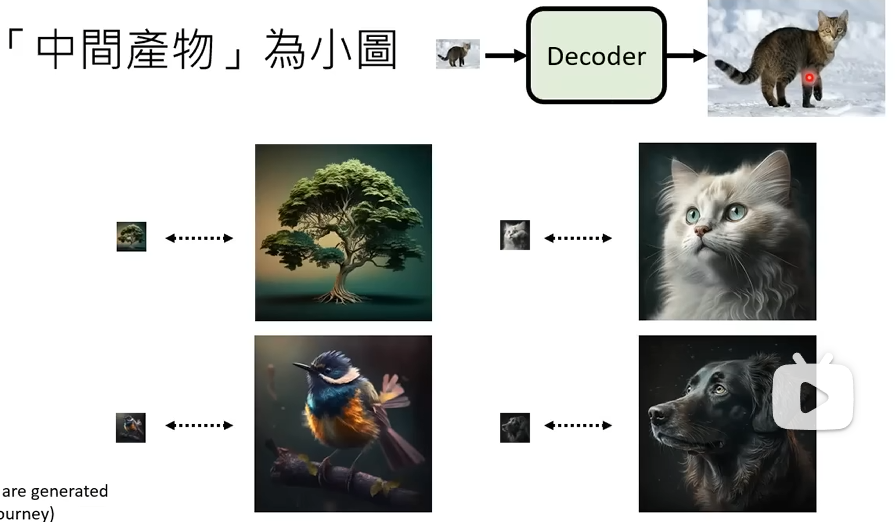
- 如果 latent representation( 潜在表示 ) 是一个小图,那 Decoder 只需要训练把小图变为大图的 Decoder。
- 如果不是小图,那就需要训练一个 Auto-encoder.