自注意力机制 ¶
约 463 个字 80 行代码 预计阅读时间 3 分钟
输入和输出向量数量相同,输出的每一个向量都考虑了输入的所有向量,简单框架如下
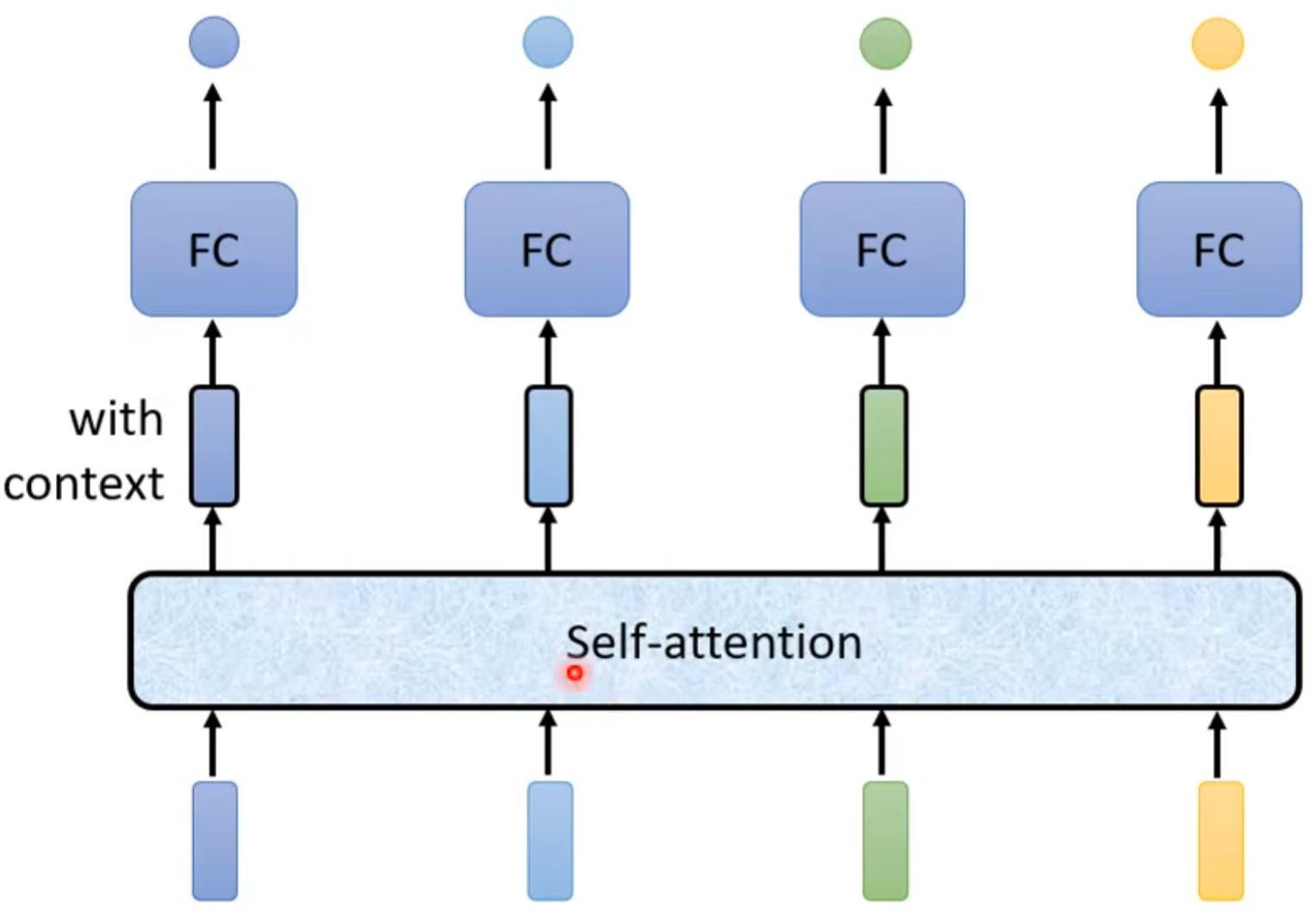
框架 ¶
输入到输出推导 ¶
我们希望考虑所有的输入向量,但是又不希望所有的信息全部输入,因此引入关联参数 \(\alpha\),这个向量决定了 \(a^1\) 分别与另外几个输入的关联程度

\(\alpha\) 的计算则引出了最为关键的三个向量 \(q\)、 \(k\)、\(v\) ,下面是一个主流的计算方法,引入矩阵 \(W^q\)、\(W^k\)、\(W^v\)
- 查询(Query,Q):当前需要处理的信息,是模型“想要找什么”的核心依据。
- 键(Key,K):输入序列的特征表示,用于和 Query 计算相关性(判断“哪些信息和当前需求相关”
) 。 - 值(Value,V):输入序列的特征表示,是最终要提取的信息,会根据相关性权重加权求和。

下面是求第一个词与四个词之间的关联度,在进行 softmax 规则化处理,得到 attention 的分数
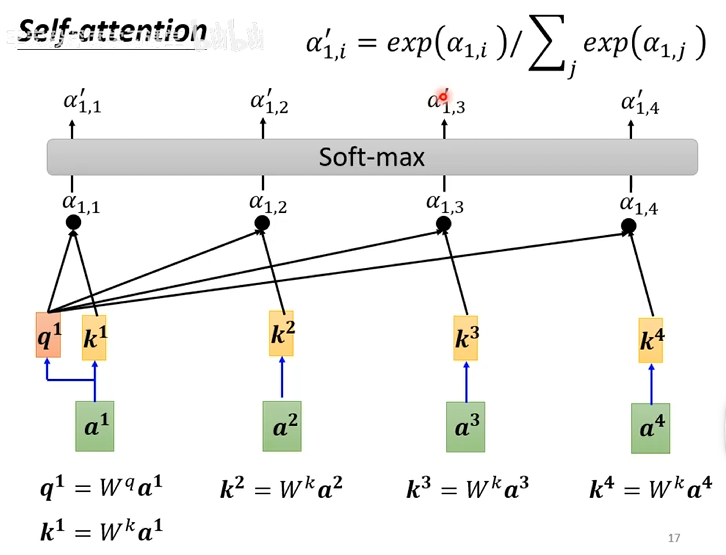
得到分数后,再求 \(b^1\)
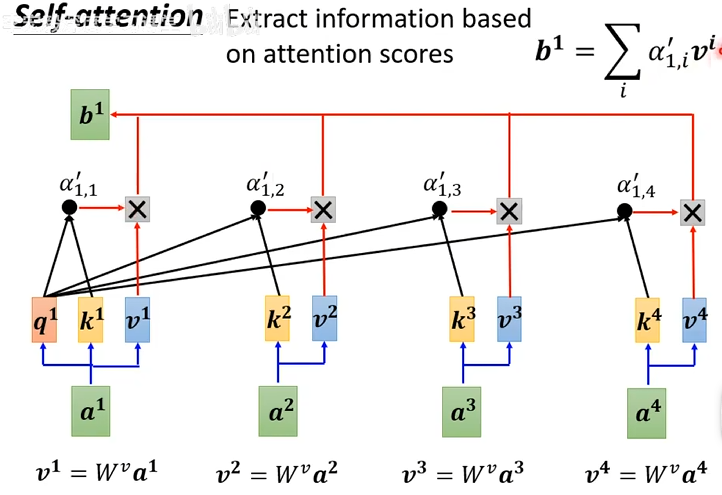
然后依次可以得到所有的 \(b^i\)
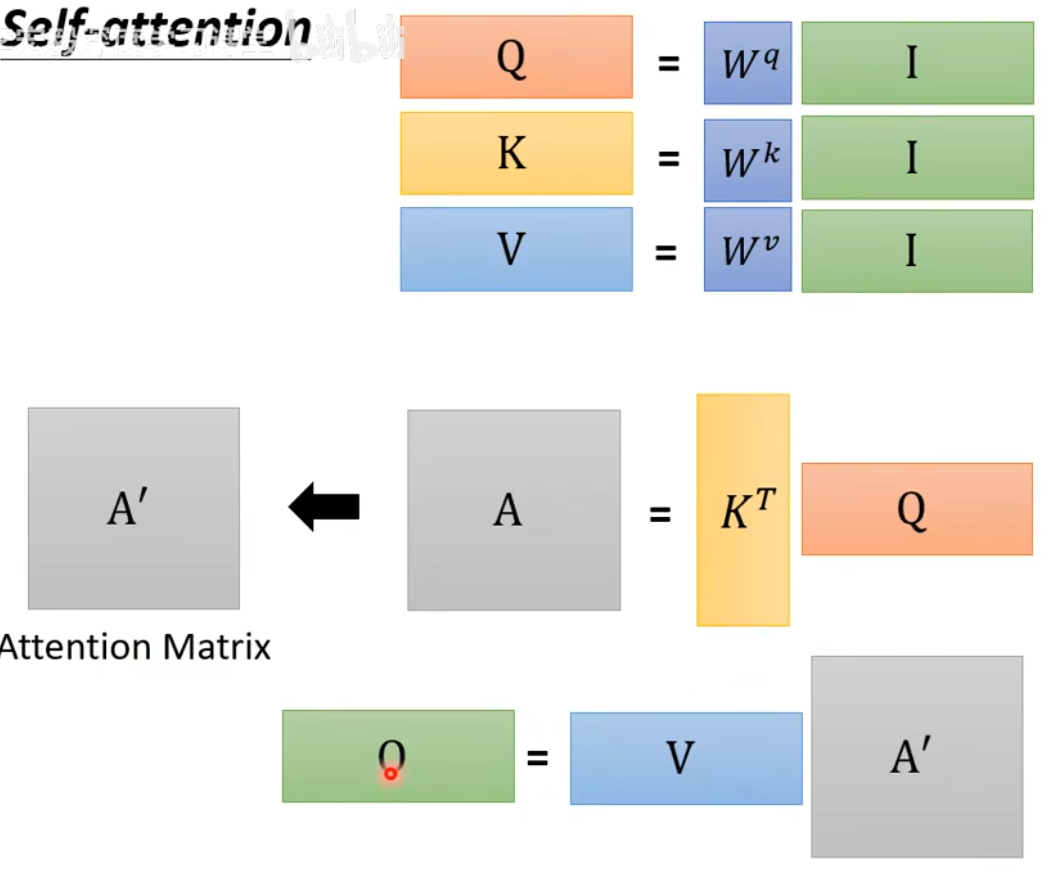
矩阵形式 ¶
其中 \(I\) 代表输入,\(A\) 的每一列对应每一个 \([\alpha_{i,1},\alpha_{i,2},\alpha_{i,3},\alpha_{i,4}]\)
Multi-head Self-attention¶
在上面的 Self-attention 中,我们是用 \(q\) 去找相关的 \(k\),但是相关有很多不同的定义,因此这里提出 Multi-head Self-attention,引入多组 \(q,k,v\)
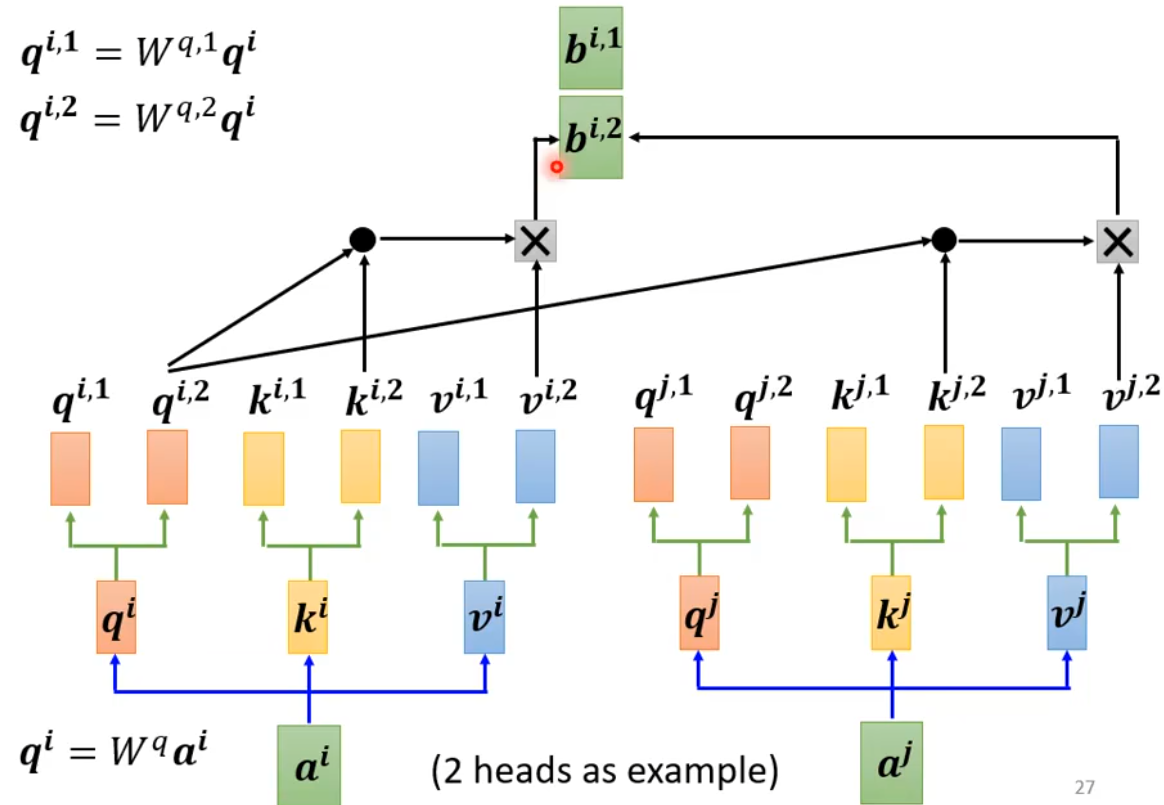
对 Self-attention 的缺陷
缺少了每一个 Input 在 Sequence 的位置信息
Self-attention 和 attention 的区别
attention 只规定了后面对于 \(QKV\) 三个矩阵运算规则,没有规定这三个矩阵是怎么得来的 而Self-attention则规定了\(QKV\)三个矩阵是同源的,都是由X乘不同矩阵得到的
代码 ¶
import torch
import torch.nn as nn
# 定义多头注意力层
class MultiHeadAttention(nn.Module):
# 初始化
# dim: 输入向量的维度
# num_heads: 注意力头数
# dropout: 防止过拟合
def __init__(self, dim, num_heads, dropout=0.1):
super().__init__()
# 确保维度能被头数均分
assert dim % num_heads == 0
# 保存基础参数
self.dim = dim # 输入总维度
self.num_heads = num_heads # 头数
self.head_dim = dim // num_heads # 每个头的维度(均分后)
# 三个线性层:把输入分别变成 Q, K, V
self.w_q = nn.Linear(dim, dim)
self.w_k = nn.Linear(dim, dim)
self.w_v = nn.Linear(dim, dim)
# dropout层
self.dropout = nn.Dropout(dropout)
# 前向传播(真正计算)
def forward(self, q, k, v, mask=None):
# 获取形状:B=批次大小,L_q=查询序列长度
B, L_q, _ = q.shape
# K和V的序列长度
L_kv = k.shape[1]
# ====================== 1. 线性变换 ======================
# 把输入通过线性层,变成查询Q、键K、值V
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
# ====================== 2. 拆分成多个头 ======================
# view:把维度拆成 [批次, 长度, 头数, 单头维度]
# transpose:交换维度 → [批次, 头数, 长度, 单头维度](方便计算)
# 最终维度:[B, num_heads, L_q, head_dim]
q = q.view(B, L_q, self.num_heads, self.head_dim).transpose(1, 2)
# 最终维度:[B, num_heads, L_kv, head_dim]
k = k.view(B, L_kv, self.num_heads, self.head_dim).transpose(1, 2)
# 最终维度:[B, num_heads, L_kv, head_dim]
v = v.view(B, L_kv, self.num_heads, self.head_dim).transpose(1, 2)
# ====================== 3. 计算注意力分数 ======================
# Q × K的转置 = 算相似度
# 除以 √head_dim = 防止数值太大
# ----------------- 重点:attn 每一步维度解释 -----------------
# attn 初始计算维度:[B, num_heads, L_q, head_dim] @ [B, num_heads, head_dim, L_kv]
# 矩阵相乘后 → attn = [B, num_heads, L_q, L_kv]
# 含义:每个查询,对每个键的注意力分数
attn = (q @ k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
# 掩码:屏蔽不需要的位置,维度仍然保持:[B, num_heads, L_q, L_kv]
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
# softmax:把分数变成权重,维度不变:[B, num_heads, L_q, L_kv]
attn = torch.softmax(attn, dim=-1)
# dropout:随机失活,维度不变:[B, num_heads, L_q, L_kv]
attn = self.dropout(attn)
# ====================== 4. 加权求和 + 拼接输出 ======================
# 注意力权重 × V
# attn 维度:[B, num_heads, L_q, L_kv]
# V 维度:[B, num_heads, L_kv, head_dim]
# 相乘后 out 维度:[B, num_heads, L_q, head_dim]
out = attn @ v
# 把多头拼回去:[B, num_heads, L_q, head_dim] → [B, L_q, dim]
out = out.transpose(1, 2).contiguous().view(B, L_q, self.dim)
return out